Les mathématiques cachées du football
Poisson, Voronoi, minimax et dix mille Sénégals simulés : une théorie complète du jeu le plus beau, et le plus aléatoire, de la planète
En plus de soixante-dix ans, la théorie des probabilités, la statistique, la géométrie, la théorie des jeux et l'apprentissage automatique sont discrètement devenus la seconde langue du football. En prenant la Coupe du monde 2026 comme laboratoire en direct, et le moteur de prédiction de FootDigest comme fil narratif, cet article bâtit la théorie mathématique complète du jeu : de la structure de Poisson des buts et de l'imprévisibilité mesurée du football, aux cotes de Dixon–Coles, aux futurs de Monte Carlo, à la trigonométrie des buts attendus, à la valeur de possession de Markov, à la géométrie de l'espace et à l'équilibre minimax du penalty, jusqu'à un bilan honnête de là où s'arrêtent les mathématiques.
La nuit où j'ai vu une distribution s'effondrer : la probabilité de victoire du Sénégal, minute par minute. Elle a culminé près de 92 % à la 79e minute. Elle a fini à zéro. Faites glisser le long du graphique pour rejouer n'importe quel instant.
« Au football, la pire des cécités, c’est de ne voir que le ballon. » Nelson Falcão Rodrigues
Prologue : Seattle, 79e minute
Dans la nuit du 1er juillet 2026, à Seattle, j’ai vu une distribution de probabilités s’effondrer en temps réel.
Le Sénégal menait 2–0 face à la Belgique, en seizièmes de finale de la Coupe du monde. Mon modèle, celui que je bâtissais depuis des mois dans FootDigest, avait abordé ce match en faisant des Sénégalais des outsiders, à peine 31 % de chances face à une Belgique plus forte. Mais une avance de deux buts à dix minutes de la fin rebat les cartes. Non parce que le modèle aimait le Sénégal (les modèles n’aiment personne, ce qui est à la fois leur vertu et leur tragédie), mais parce que l’histoire est d’une brutale clarté sur ce qui arrive quand une équipe mène de deux buts si tard dans un match à élimination directe : elle tient plus de neuf fois sur dix. Elle ne perd presque jamais.
Presque est le mot le plus important de tout cet article.
La Belgique a marqué deux fois en trois minutes. Prolongations. Puis un penalty (chaotique, contesté, le genre de décision qu’on rejugera dans les salons de Dakar pendant une décennie) et c’était fini. Belgique 3, Sénégal 2. La queue de la distribution était arrivée, vêtue de rouge.
Voici ce que personne ne vous dit sur la construction de modèles de prédiction au football : le moment où ils vous font le plus mal est le moment où ils fonctionnent parfaitement. Un événement à une chance sur dix est censé survenir une fois sur dix. S’il ne survenait jamais, mon modèle serait cassé. Et pourtant, assis là à regarder le visage de Sadio Mané au coup de sifflet final, aucune partie de moi n’était consolée par des courbes de calibration.
Cet article parle de cette tension. Il parle de la façon dont, en plus de soixante-dix ans, la théorie des probabilités, la statistique, la géométrie, la théorie des jeux et l’apprentissage automatique sont discrètement devenus la seconde langue du football, et de ce que cette langue peut et ne peut pas dire. Je prendrai cette Coupe du monde, celle qui se déroule encore à travers l’Amérique du Nord au moment où j’écris, comme laboratoire. Je prendrai FootDigest, la plateforme d’analyse que je bâtis à travers elle, comme fil narratif, parce qu’il n’y a pas de meilleure façon de comprendre ces idées que d’avoir son propre modèle publiquement, douloureusement dans l’erreur. Et je m’efforcerai de tenir cet essai au même standard que le produit : des chiffres réels et sourcés, ou une absence assumée. Chaque affirmation empirique ci-dessous est soit citée à partir d’un article précis, soit tirée des archives publiques de ce tournoi, soit explicitement étiquetée comme illustrative.
Nous commençons dans les années 1950, avec un statisticien qui remarqua quelque chose d’étrange au sujet des buts.
Trois promesses, pour que vous sachiez ce que vous tenez :
Un, les mathématiques sont réelles. Là où je donne une équation, c’est la vraie équation, pas un geste vers elle. Là où je simplifie, je le dis. L’annexe contient une spécification complète du modèle de FootDigest (ses données, ses paramètres et son protocole de validation) dans le format que les chercheurs en apprentissage automatique appellent une fiche de modèle, parce qu’une prédiction que vous ne pouvez pas auditer est une opinion avec des étapes en plus.
Deux, les affirmations sont falsifiables. Un modèle probabiliste gagne la confiance d’une seule manière : ses prédictions à 70 % doivent se réaliser environ 70 % du temps, mesurées sur des centaines de matchs. Je vous montrerai les règles de notation qui rendent cette phrase précise, et là où les modèles, le mien compris, échouent.
Trois, le football passe d’abord. Chaque abstraction de cet article est ancrée dans un moment de cette Coupe du monde : une frappe de Nicolas Jackson contre le poteau à New York, une décision de VAR dans le temps additionnel qui a réordonné le groupe G pour la septième fois en une soirée, deux séances de tirs au but la même nuit qui ont validé un théorème de 1928. Si les mathématiques cessent d’éclairer le jeu et se mettent à le remplacer, j’aurai échoué, et vous devriez le dire dans les commentaires.
La notation, une fois, pour ne jamais trébucher dessus : λ (lambda) est un taux de buts attendus ; α et β sont les cotes d’attaque et de défense d’une équipe ; θ (thêta) est un angle géométrique ; P(·) est une probabilité ; E[·] est une espérance. Voilà tout l’alphabet dont nous avons besoin.
PARTIE I : LE HASARD
Pourquoi le football est le sport majeur le plus imprévisible de la planète (c’est mesurable)
I.1 · Les ruades de la cavalerie prussienne
En 1837, Siméon Denis Poisson publia un traité sur la probabilité des verdicts judiciaires. Enfouie à l’intérieur se trouvait une distribution décrivant des événements rares, indépendants, survenant à un taux moyen constant. Ladislaus Bortkiewicz la rendit célèbre en 1898 en montrant qu’elle décrivait parfaitement les décès par ruade de cheval dans la cavalerie prussienne : des événements si rares, si indépendants, si régulièrement répartis que leur chaos avait une forme.
La loi de Poisson dit : si des événements surviennent à un taux moyen λ par unité d’exposition, la probabilité d’en observer exactement k est
Un seul paramètre. La moyenne de la distribution est λ et (c’est la signature) sa variance est aussi λ. Si vous voulez un jour tester si un processus de comptage suit une loi de Poisson, vérifiez si sa variance égale sa moyenne. Gardez cette idée.
D’où vient cette formule ? Elle n’est pas arbitraire ; c’est ce que la loi binomiale devient à la limite de la rareté. Découpez un match de football en n minuscules intervalles, chacun ayant une petite probabilité p = λ/n de contenir un but. Le nombre de buts suit une loi binomiale(n, p). Faites tendre n → ∞ pendant que λ = np reste fixe (une infinité d’instants, chacun presque jamais décisif) et la binomiale converge vers la Poisson. Un match de football est cette limite faite chair : quatre-vingt-dix minutes et plus de quasi-occasions discrétisées en deux ou trois événements réels. La Poisson n’est pas un modèle que nous imposons au football. C’est ce que la structure du football implique.
La première équation, rendue interactive. Faites glisser λ, les buts moyens par match, et regardez la probabilité de chaque nombre de buts se redessiner. Remarquez que la moyenne et la variance restent égales, la signature de la distribution. À λ ≈ 2,5 (moyenne d’une Coupe du Monde), un 0–0 survient encore environ 8 % du temps.
I.2 · 1956 : le premier à vérifier
Le premier à réellement tester cela contre des données de football fut M.J. Moroney [1] (1956). Facts from Figures. Penguin. The first serious statistical treatment of football scores; Poisson and negative binomial fits. , dans son livre de 1956 Facts from Figures : ajustez une Poisson à des scores de championnat anglais et ça marche, bien, quoique pas parfaitement. Les vrais décomptes de buts sont légèrement surdispersés (variance un peu au-dessus de la moyenne ; la loi binomiale négative ajuste mieux la queue), une ride dont la cause (les équipes diffèrent par leur qualité, et les situations de jeu rétroagissent sur les taux de but) alimentera les cinquante années de raffinements suivantes. Mais en première approximation, un seul nombre par équipe et par match capture le processus de marque du sport collectif le plus complexe du monde. Cela devrait être stupéfiant. Ça le devient encore plus.
Douze ans plus tard vint le traumatisme fondateur du domaine. Charles Reep, comptable de la Royal Air Force, avait passé deux décennies à annoter des matchs à la main (des centaines, au crayon, dans une sténographie privée) et publia en 1968, avec Bernard Benjamin, « Skill and Chance in Association Football » [2] (1968). Skill and Chance in Association Football. JRSS-A 131. The founding paper and the founding fallacy; read it alongside its critics as a permanent vaccine against denominator neglect. dans le Journal of the Royal Statistical Society. Leur résultat phare : environ 80 % des buts venaient d’actions de trois passes ou moins. La conclusion de Reep : la passe est surestimée ; portez le ballon vers l’avant, vite. Le football anglais a écouté. L’ère du jeu long, des décennies durant, remonte intellectuellement à cet article.
Le résultat était vrai. La conclusion était fausse. Environ 80 % (plus, en réalité) de toutes les possessions sont de trois passes ou moins, donc bien sûr que la plupart des buts en viennent : les possessions courtes dominent le dénominateur. Conditionnez correctement, et les séquences de passes plus longues convertissent à un taux plus élevé par possession. Reep avait découvert le taux de base et l’avait pris pour un avantage ; l’analyse du football est née en tenant une probabilité conditionnelle par le mauvais bout.
Je garde l’histoire de Reep affichée au-dessus de mon bureau, métaphoriquement, pendant que je construis FootDigest, parce que c’est l’avertissement permanent du domaine : les données étaient justes, le comptage était juste, et l’inférence a détruit une génération de football anglais. La statistique descriptive sans raisonnement probabiliste n’est pas neutre. C’est des munitions au service de ce que vous croyiez déjà.
I.3 · Quantifier le chaos : la fréquence des surprises
Donc les buts au football suivent approximativement une loi de Poisson, et ils sont rares, autour de deux et demi par match lors des dernières Coupes du monde. Pourquoi la rareté importe-t-elle tant ? Parce qu’elle fait du football, par mesure directe, le sport majeur le plus imprévisible de la planète.
Ce n’est pas de la rhétorique ; ça a un chiffre. En 2006, trois physiciens de Los Alamos ( Ben-Naim, Vazquez et Redner [6] (2006). Parity and Predictability of Competitions. J. Quantitative Analysis in Sports 2(4). 300,000+ matches; football measured as the major sport with the highest upset frequency. ) ont analysé l’intégralité des archives historiques de cinq ligues (plus de 300 000 matchs, dont plus d’un siècle de football anglais de première division) et ont calculé la fréquence des surprises de chaque sport : la fréquence à laquelle l’équipe au moins bon bilan bat celle au meilleur bilan. Le football anglais avait la plus haute fréquence de surprises des cinq ligues étudiées, environ 45 %, le baseball juste derrière, et le football américain et le basketball les plus prévisibles, près de 36 %. Le football tirait aussi près d’un quart de ses matchs (24,6 %), un taux de nul d’un ordre de grandeur au-delà de celui de la NFL.
À quelle fréquence l’équipe la moins bonne l’emporte, dans les cinq ligues de l’étude citée ci-dessus (Ben-Naim, Vazquez et Redner, 2006). Le football est le plus proche de la ligne du pile ou face : sa romance, c’est sa variance.
Réfléchissez à ce que q ≈ 0,45 signifie : la moins bonne équipe gagne presque la moitié des fois où le match n’est pas nul. Le football est plus proche du pile ou face qu’aucun sport professionnel d’une richesse comparable. Et le mécanisme est exactement la rareté de Poisson : le basketball produit ~90 événements de marque par match, et la loi des grands nombres broie la chance en poussière ; le football en produit deux ou trois, et l’échantillon est bien trop petit pour que le talent domine de façon fiable la variance. L’avantage de la meilleure équipe est réel. Il vit simplement dans l’espérance, et un seul match échantillonne à peine cette espérance.
Ce seul fait mesuré explique presque tout ce qui est étrange dans ce sport, y compris l’essentiel de la phase de groupes de cette Coupe du monde :
- Le Sénégal perdant contre la France et la Norvège, puis battant l’Irak 5–0, première nation africaine à marquer cinq fois dans un match de Coupe du monde, et se qualifiant comme seule équipe troisième à trois points.
- Le Maroc tenant les Pays-Bas en échec 1–1 et gagnant aux tirs au but ; le Paraguay faisant exactement la même chose à l’Allemagne, la même nuit.
- L’Afrique du Sud, quatrième de son groupe au coup d’envoi de la dernière journée, atteignant les phases à élimination directe pour la première fois de son histoire grâce à un unique but à la 63e minute.
Des taux de marque faibles signifient que le chemin de la victoire pour l’équipe la plus faible n’exige pas d’être meilleure : il exige que les dés de Poisson tombent avec bienveillance sur une poignée de moments décisifs. La romance du football est sa variance. Les mathématiques ne tuent pas la magie. Elles la localisent, et lui mettent un chiffre : 0,45.
Mais un seul λ par équipe est un instrument grossier. Pour prédire un match réel (France contre Sénégal, le 16 juin, groupe I), λ doit dépendre de qui joue contre qui. Entre en scène le modèle qui fait tourner la salle des machines de FootDigest.
PARTIE II : LES COTES
Dixon–Coles : le modèle de soixante lignes qui bat encore les réseaux de neurones
II.1 · D’un seul λ à un modèle complet
La lignée passe par deux articles. En 1982, Michael Maher (Statistica Neerlandica) [3] (1982). Modelling Association Football Scores. Statistica Neerlandica 36. Attack/defence Poisson structure; the skeleton of everything since. proposa l’idée structurelle : donnez à chaque équipe i une force d’attaque αᵢ et une faiblesse défensive βᵢ, et modélisez les buts de chaque camp dans un match comme des Poisson indépendantes dont les taux multiplient la force de l’attaquant par la faiblesse du défenseur. En 1997, Mark Dixon et Stuart Coles (Journal of the Royal Statistical Society, Series C) [4] (1997). Modelling Association Football Scores and Inefficiencies in the Football Betting Market. JRSS-C 46. The workhorse: τ correction, time decay, and a demonstration of market inefficiency in one paper. transformèrent la structure de Maher en un instrument de prévision assez tranchant pour que la seconde moitié de leur article démontre qu’il trouve des inefficiences exploitables sur le marché britannique des paris. Près de trente ans plus tard, il reste la référence que chaque architecture à la mode doit battre, et n’y parvient souvent pas.
Quand l’équipe i reçoit l’équipe j :
Les buts de chaque camp suivent une Poisson de ces taux, et la probabilité d’un score exact (h, a) est leur produit, multiplié par une correction cruciale ci-dessous. Une note technique qui sépare une vraie implémentation d’un billet de blog : les paramètres ne sont pas identifiables tels quels (doublez chaque α, divisez chaque β par deux, rien ne change), donc vous imposez une normalisation : par convention, les cotes d’attaque ont une moyenne de 1. Petit détail ; sans lui, votre optimiseur erre à jamais dans une vallée plate.
Vous estimez les paramètres par maximum de vraisemblance : choisissez les α, les β, le γ qui rendent les scores historiquement observés conjointement aussi probables que possible. Formellement, avec le match m opposant les équipes i(m), j(m), de score (h_m, a_m) et d’âge t_m, vous maximisez la log-vraisemblance pondérée
Soixante lignes de Python et un appel à scipy.optimize.minimize. C’est vraiment tout le moteur. Les deux raffinements qui l’habitent sont là où réside le métier :
La correction des scores faibles τ. Des Poisson indépendantes sous-estiment systématiquement les nuls, surtout le 0–0 et le 1–1, parce que quand aucun camp ne marque, c’est souvent que les deux se sont repliés dans la prudence : au bas de l’échelle, les buts sont négativement dépendants. Dixon et Coles corrigent exactement, et uniquement, les quatre cellules de scores faibles :
Cela ressemble à un vilain bricolage. Ça en est un. Cela répare aussi le plus grand biais systématique des modèles de Poisson au football, et il y a là une leçon de conception : les meilleurs modèles statistiques sont honnêtes sur l’endroit précis où leurs hypothèses craquent, et corrigent exactement là, pas plus large.
La décroissance temporelle. Un résultat de 2023 en dit moins sur une équipe aujourd’hui qu’un résultat du mois dernier, donc les matchs passés sont sous-pondérés exponentiellement : poids = e^(−ξt). Réglez ξ trop bas et votre modèle croit que la Belgique est encore la machine demi-finaliste de 2018 ; trop haut et il panique après une seule mauvaise soirée. Quand j’ai ajusté le moteur de FootDigest, choisir ξ tenait moins de la statistique que de décider combien de temps l’âme d’une équipe persiste. (Empiriquement, à travers mes backtests, la réponse est une demi-vie de l’ordre d’un an. Faites-en ce que vous voulez.)

Figure 1 : déplacez les cotes et regardez la surface des scores respirer. Chaque probabilité en aval dans cet article est une somme sur cette unique matrice.
II.2 · Les rivaux : Poisson bivarié et Elo
La rigueur exige de nommer les alternatives et de dire pourquoi FootDigest ne les utilise pas.
Poisson bivarié ( Karlis et Ntzoufras, 2003, JRSS-D [5] (2003). Analysis of Sports Data by Using Bivariate Poisson Models. JRSS-D 52. The principled alternative to τ. ) traite les scores des deux équipes comme partageant une composante latente commune : les deux décomptes reçoivent un choc commun de « tempo de match », ce qui modélise la corrélation des scores plus élégamment que le bricolage de τ. Il ajuste mieux dans l’échantillon ; les gains de prévision hors échantillon sur Dixon–Coles sont systématiquement marginaux, et le modèle est plus dur à ajuster et à expliquer. Le principe de conception de FootDigest est que chaque choix de modélisation doit être explicable en un paragraphe sur une page d’équipe. τ l’emporte.
Elo (le classement des échecs adapté au football, et depuis 2018 la base officielle du classement mondial FIFA) est le cousin minimaliste de Dixon–Coles : un seul nombre par équipe, mis à jour après chaque match par K·(résultat − résultat attendu). Ses vertus sont la robustesse et l’absence de réajustement. Son coût est le silence : Elo prédit qui gagne mais ne dit rien des scores, et ce sont les scores qu’il faut échantillonner pour simuler des classements de groupe, des départages et des différences de buts. Pour la simulation de tournoi, un modèle de buts n’est pas une préférence. C’est une exigence.
II.3 · Ce que le modèle disait vraiment du groupe I
Passé dans le moteur ajusté avant le tournoi, le groupe du Sénégal se lisait comme un piège : la France (α d’élite, β d’élite), la Norvège (une attaque monstrueuse concentrée en un seul homme, une violation ambulante de l’hypothèse de taux constant nommée Haaland), l’Irak (le donneur de λ désigné du groupe). Le chemin modal du modèle pour le Sénégal était précisément celui qui s’est produit : des défaites disputées contre les deux nations européennes, une large victoire sur l’Irak, la troisième place, trois points, et une prière.
La défaite 3–1 contre la France était presque une simulation médiane. Jackson a frappé le poteau ; Ismaïla Sarr a expédié dans les tribunes une occasion de six mètres juste avant la mi-temps ; Mbappé a converti ce qu’on lui a donné avec la froideur qui fait de lui une réfutation à lui seul des taux moyens. Le score disait 3–1. La qualité des occasions disait quelque chose de plus proche d’un pile ou face que la France a bien appelé : un écart que nous rendrons précis en Partie V, parce que cet écart est toute la raison d’être des buts attendus.
Choisissez deux équipes et lisez le match. Les cotes sont illustratives, mais la chaîne qui les transforme en score (la suprématie Elo en deux taux de buts, puis la matrice Dixon–Coles corrigée par τ) est le vrai modèle. Il s’ouvre sur Sénégal contre Belgique : les 31 % qui ont tout déclenché.
PARTIE III : LE JUGEMENT
Comment noter un prévisionniste (ou : pourquoi « tu t’es trompé » n’est pas un argument)
Avant de simuler quoi que ce soit, une question inconfortable : qu’est-ce que cela veut dire, au juste, qu’une prévision probabiliste soit bonne ? « Le modèle disait Sénégal 62 % et le Sénégal a perdu » n’est pas une réfutation, pas plus que survivre à un tour de roulette russe ne réfute le danger. Des résultats isolés ne peuvent pas falsifier des probabilités. Seules des populations de prévisions le peuvent. Trois instruments rendent cela précis, et ils sont l’arbitre réel de FootDigest :
Le score de Brier : l’erreur quadratique moyenne entre les probabilités prévues et les issues (1 si elle est survenue, 0 sinon). Plus bas, mieux c’est. Il punit la confiance dans le mauvais sens de façon quadratique, ce qui est exactement le ressenti qu’il faut.
Le Ranked Probability Score (RPS) : le standard spécifique au football, parce que les issues victoire / nul / défaite sont ordonnées : prédire une victoire à domicile quand le match est nul est moins faux que la prédire quand l’équipe visiteuse gagne. Pour des probabilités prévues cumulées Fₖ et des issues cumulées Oₖ sur les issues ordonnées :
Réglez une prévision, choisissez le résultat, et regardez les pénalités de Brier et de RPS bouger. Être confiant et se tromper coûte le plus cher, et c’est tout l’intérêt : un seul résultat ne peut pas réfuter une probabilité, mais une règle de notation le peut, en masse.
La calibration : la plus profonde des trois. Rassemblez chaque match que votre modèle a estimé à ~70 %, et vérifiez : environ 70 % d’entre eux se sont-ils produits ? Répétez sur chaque tranche de probabilité. Un modèle est calibré quand sa confiance affichée correspond partout à sa fréquence réalisée. La calibration est le seul sens dans lequel un modèle probabiliste peut avoir « raison », et elle n’est vérifiable qu’en masse : des centaines de matchs, ce qui explique pourquoi le moteur Dixon–Coles de FootDigest n’a été mis en ligne qu’après un backtest sur des saisons entières de rencontres historiques, noté au RPS contre une référence naïve et contre le seul adversaire qui compte.
À titre indicatif. Faites glisser le curseur et regardez un modèle calibré se déformer en un modèle trop confiant. Un modèle est honnête quand ses prédictions à 70 % se réalisent environ 70 % du temps : plus la courbe épouse la diagonale, mieux c’est.
Cet adversaire, c’est le marché des paris. Les cotes au coup d’envoi, moyennées entre bookmakers et débarrassées de la marge, sont la prévision de football la plus solide accessible publiquement : un marché de prédiction agrégeant des milliers de modèles et d’initiés. Le standard professionnel pour un modèle est brutal et simple : bat-il la cote de clôture ? Des décennies de littérature sur l’efficience (le second acte de Dixon et Coles eux-mêmes) disent que la réponse est le plus souvent non, parfois, localement, oui, et tout produit d’analyse qui refuse de publier ses scores contre cette référence demande de la foi au lieu d’offrir des preuves. FootDigest publie ses backtests. Ce paragraphe en est la raison.
PARTIE IV : LA SIMULATION
Monte Carlo : dix mille Sénégals
IV.1 · La méthode née du nom d’un casino
La méthode de Monte Carlo est née à Los Alamos dans les années 1940, quand Stanisław Ulam (en convalescence, jouant au solitaire) s’interrogea sur la probabilité de gagner une donne donnée. La combinatoire était sans espoir. Son intuition : jouez simplement une centaine de mains et comptez. Nicholas Metropolis a nommé la méthode d’après le casino où l’oncle d’Ulam a dilapidé l’argent de la famille au jeu, ce qui reste la décision de nommage la plus honnête de l’histoire des mathématiques appliquées.
Le principe : quand une probabilité est trop enchevêtrée pour être calculée sous forme close, simulez le monde de nombreuses fois et comptez. La loi des grands nombres garantit la convergence, et le théorème central limite vous dit à quelle vitesse : l’erreur standard d’une proportion estimée p̂ sur N simulations est
À N = 10 000, les probabilités portent une erreur standard sous le demi-point de pourcentage. Pour un traqueur de qualification grand public, c’est de la précision en réserve ; l’erreur systématique du modèle éclipse son erreur d’échantillonnage, ce qui nous amène à la partie que la plupart des simulateurs publics ratent en silence.
IV.2 · Les deux couches d’incertitude
Une simulation de tournoi contient deux formes distinctes de non-savoir, et les confondre est le péché capital du genre :
L’incertitude aléatoire : les dés. Même avec des cotes parfaites, les issues des matchs sont des tirages aléatoires. C’est l’incertitude que les 10 000 simulations échantillonnent.
L’incertitude épistémique : les cotes elles-mêmes sont des estimations, ajustées sur des données finies et qui se déprécient. Le « vrai » α du Sénégal n’est pas un nombre que mon optimiseur a trouvé ; c’est un nombre que mon optimiseur a approximé, avec des barres d’erreur. Une chaîne rigoureuse propage cela en tirant aussi les paramètres depuis leur distribution estimée (ou des réajustements par bootstrap) avant de simuler chaque monde. Sinon vos 4 % sont en réalité « 4 %, à condition que mes estimations ponctuelles soient exactement justes », ce qu’aucune n’est jamais. C’est l’idéal ; le moteur livré de FootDigest n’échantillonne aujourd’hui que la première couche (voir l’Annexe A), et élargir la probabilité affichée à la seconde est au programme. La probabilité affichée honnête est plus large que la naïve, et l’honnêteté sur la largeur est une fonctionnalité.
La chaîne, de bout en bout :
- Ajuster Dixon–Coles sur des résultats internationaux pondérés dans le temps.
- Tirer un vecteur de paramètres depuis sa distribution d’incertitude.
- Pour chaque match non joué, calculer λ_home, λ_away, et tirer un score depuis le modèle corrigé par τ. Pas le score le plus probable, un score aléatoire, en proportion de sa probabilité. La distinction est primordiale : le score modal dans la plupart des matchs est 1–1 à ~11 %, et ne simuler que les issues probables effacerait précisément le chaos que nous cherchons à mesurer.
- Appliquer les règles : classements de groupe, départages en confrontation directe, différence de buts, classement des huit meilleurs troisièmes, le tableau final. Cette étape est la masse ingrate du code, des centaines de lignes transcrivant la réglementation de la FIFA, et c’est là que la plupart des modèles publics échouent en silence. Un simulateur qui tire de beaux scores de Poisson puis bâcle le départage des troisièmes est un beau mensonge.
- Répéter 10 000 fois. Compter.
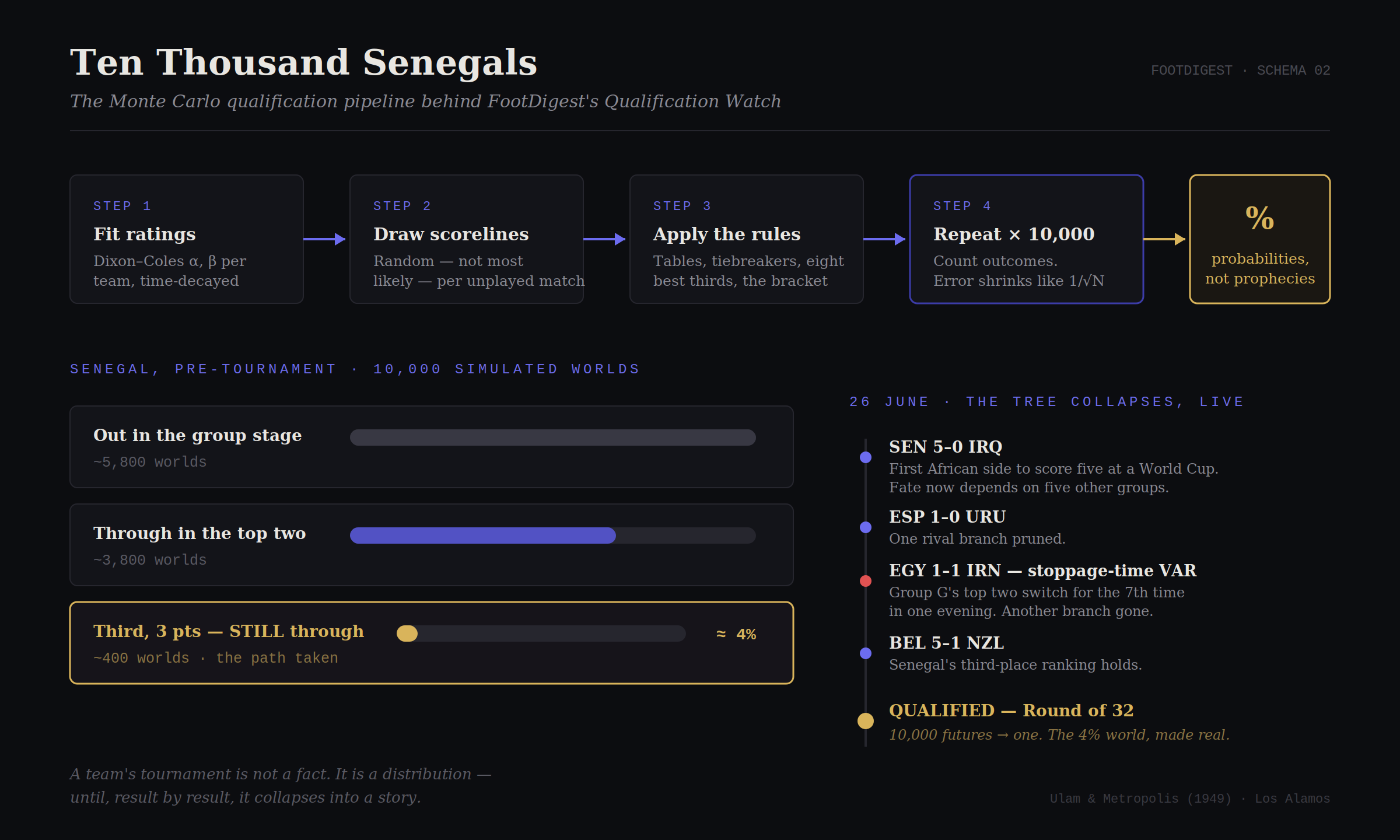
Figure 2 : appuyez sur le bouton. Dix mille mondes, comptés. La graine est à vous de changer ; la convergence, non. (Groupe illustratif, pas le moteur en direct.)
Maintenant, tout le tournoi. Un tableau illustratif à 16 équipes, ensemencé par des cotes Elo illustratives et joué des milliers de fois, pour que la force brute et la chance du tirage façonnent ensemble les chances de titre de chaque équipe. Le Sénégal est mis en évidence. Regardez les barres se réordonner à mesure que le décompte monte. Pas le moteur en direct.
IV.3 · Le 26 juin, comme un courant de probabilités
Regardez maintenant la machinerie rencontrer la réalité. Après la phase de groupes, le Sénégal comptait trois points, +2 de différence de buts, et un destin entièrement entre les mains d’autres groupes, dépendant des résultats finaux des groupes G, H, J, K et L. Ce n’est pas un scénario que l’intuition humaine sait chiffrer. C’est un arbre de probabilités conditionnelles s’effondrant branche par branche, en direct :
La Qualification Watch recalculait les scénarios plus vite que je ne pouvais écrire des commentaires à leur sujet.
Chaque résultat était une mesure effondrant la fonction d’onde du tournoi du Sénégal. Le vendredi soir, dix mille Sénégals simulés étaient devenus un seul réel : qualifié pour les seizièmes de finale comme seul troisième à trois points, une issue que mes simulations d’avant-tournoi avaient placée dans environ un monde sur vingt-cinq. Rare, mais représentée. Tout l’intérêt de Monte Carlo est que quelques centaines de vos futurs simulés y vivaient déjà, attendant que la réalité choisisse.
Et c’est la leçon plus profonde qu’enseigne la simulation, celle à laquelle je reviens chaque fois que j’écris sur le Sénégal pour un public sénégalais : le tournoi d’une équipe n’est pas un fait ; c’est une distribution. Le Sénégal éliminé par la Belgique en prolongation et le Sénégal qui atteignait les quarts de finale coexistaient, à une probabilité significative, jusqu’à environ 23 h, heure de Seattle, le 1er juillet. Les supporters vivent à l’intérieur d’un unique chemin échantillonné. Les modèles vivent dans tous à la fois. Le deuil, c’est ce que l’on ressent quand on est forcé de quitter la seconde vue pour revenir à la première.
PARTIE V : LA GÉOMÉTRIE D’UN INSTANT
Les buts attendus comme trigonométrie assortie d’un taux de réussite
V.1 · L’angle visible
Descendez des tournois à un seul instant. Première mi-temps, le 16 juin, New York. Nicolas Jackson, frappe basse depuis la gauche, sur le poteau, sur la jambe de Mike Maignan, en corner. Le tableau d’affichage n’enregistre rien. Qu’aurait-il dû enregistrer ?
Les buts attendus (xG) répondent à une question posée avec précision : de toutes les frappes historiques tentées depuis cette situation, quelle fraction est devenue but ? Le xG d’une frappe est cette probabilité apprise. Et avant que le moindre apprentissage automatique n’arrive, le xG est de la géométrie : précisément, la géométrie que le système nerveux d’un attaquant évalue en deux cents millisecondes et qu’un modèle calcule explicitement.
Deux variables dominent tout le reste. La distance : la probabilité de marquer décroît fortement, à peu près exponentiellement, à mesure que vous vous éloignez du but. L’angle visible : la cage mesure 7,32 mètres de large, et l’angle qu’elle sous-tend depuis votre position est, fonctionnellement, l’ouverture de la porte. Depuis un point à x mètres de la ligne de but et à y mètres latéralement du centre, l’angle sous-tendu a une forme close (une application directe de l’identité de la différence de tangentes) :
Depuis le point de penalty, θ ≈ 36°. Dérivez vers la ligne de sortie et θ s’effondre vers zéro, la cage se ferme géométriquement. Tracez les courbes de niveau de θ sur un terrain et vous obtenez des arcs emboîtés rayonnant depuis la cage : un champ de probabilités, invisible mais aussi réel que le gazon. Les attaquants d’élite sont, fonctionnellement, des algorithmes de montée de gradient sur ce champ. Regardez les déplacements de Mbappé dans le duel décisif de groupe Norvège–France et vous regardez quelqu’un surfer les contours vers la région où θ est épais et les défenseurs absents.
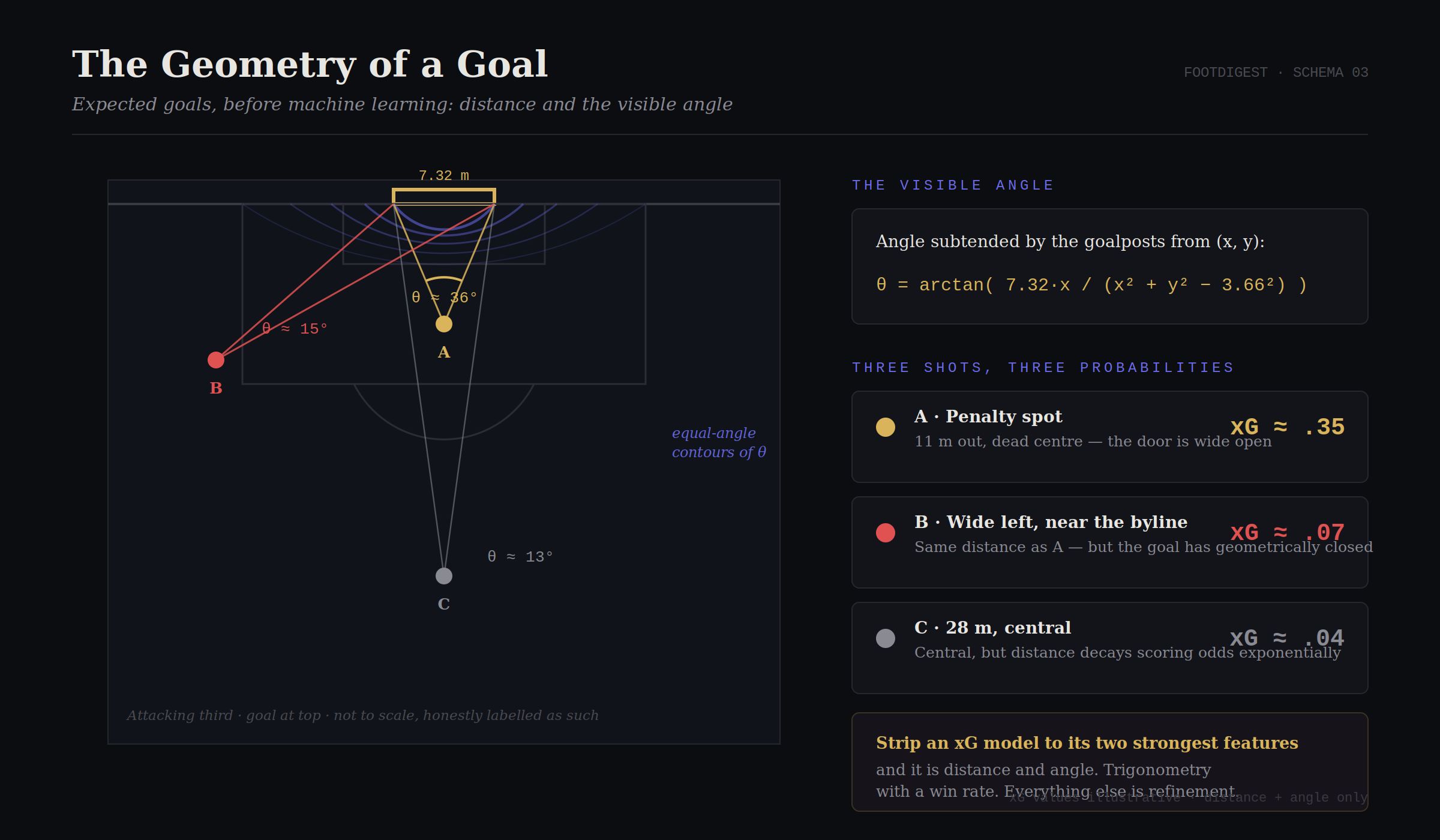
Figure 3 : déplacez la frappe. La distance érode vos chances ; l’angle visible ferme la porte. De la trigonométrie assortie d’un taux de réussite.
V.2 · De la géométrie à l’apprentissage
Les premiers modèles de xG étaient des régressions logistiques : probabilité d’un but = σ(w₀ + w₁·distance + w₂·angle + …), où σ est la sigmoïde qui écrase tout nombre réel dans (0,1). Les versions modernes sont des ensembles d’arbres à gradient boosté ajoutant la partie du corps, le type de passe décisive, la pression défensive, l’état de contre-attaque, la position du gardien et, là où existent des données de suivi, toute la géométrie défensive au moment de la frappe. Mais réduisez le modèle de n’importe quel fournisseur à ses deux variables les plus fortes et vous retrouvez la distance et l’angle. Tout ce qui a suivi depuis 2012 est un raffinement d’un cœur trigonométrique.
Trois notes de rigueur que le discours des résumés vidéo omet toujours :
Les modèles de xG sont en désaccord entre eux. Fournisseurs différents, données d’entraînement différentes, jeux de variables différents : la même frappe peut valoir 0,31 pour un modèle et 0,42 pour un autre. Une valeur de xG sans son fournisseur est un nombre sans unité. FootDigest affiche les sources sur chaque figure pour exactement cette raison.
Le biais de sélection des frappes. Le modèle apprend des frappes tentées. Mais qui tire de mauvaises positions ? De façon disproportionnée, des joueurs sans meilleure option, ou d’une confiance inhabituelle dans ce geste. Les données d’entraînement ne sont pas un échantillon aléatoire de situations ; c’est un échantillon filtré par le jugement professionnel, et le modèle hérite discrètement de ce filtre.
Le xG d’un seul match est bruité. Sommer une poignée de probabilités de Bernoulli hérite de toute la variance de la Partie I. La valeur du xG est longitudinale : sur de nombreux matchs, la création d’occasions persiste tandis que la chance à la finition revient à la moyenne, ce qui explique pourquoi l’historique de xG d’une équipe prédit mieux ses résultats futurs que ses résultats réels ne le font. C’est l’argument statistique pour juger les performances plutôt que les scores, et c’est la colline sur laquelle meurt la ligne éditoriale de FootDigest. La phase de groupes du Sénégal a produit trois points ; son profil de qualité d’occasions valait davantage. La Belgique s’en est aperçue pendant quatre-vingt-treize minutes. Les mathématiques n’offrent pas de lots de consolation, mais elles écrivent des épitaphes exactes.
PARTIE VI : LA VALEUR DE TOUT LE RESTE
Les chaînes de Markov et le prix d’une passe
Le xG a un énorme angle mort : il ne chiffre que les frappes. Mais l’essentiel du football n’est pas de tirer : c’est la fabrication patiente de positions de frappe. Que vaut une passe qui casse une ligne depuis le milieu ? Qu’a apporté la conduite de balle d’Habib Diarra à travers le milieu irakien, trois actions avant que quiconque ne tire ? La réponse moderne emprunte l’objet central de la théorie des processus stochastiques : la chaîne de Markov.
Modélisez une possession comme une marche entre états : des zones du terrain, plus deux états absorbants, but et possession perdue. La propriété de Markov suppose que le futur ne dépend que de l’état présent, pas du chemin qui y a mené (faux dans le détail, utile en masse, comme toute bonne hypothèse de cet article). Puis définissez la valeur de chaque zone z comme la probabilité qu’une possession actuellement en z produise finalement un but. Cela satisfait une équation d’auto-cohérence. Les lecteurs venus de l’apprentissage par renforcement reconnaîtront immédiatement l’équation de Bellman :
La valeur de là où vous vous tenez = la chance que vous marquiez d’ici, plus la valeur espérée de partout où vous pourriez déplacer le ballon ensuite. Estimez les probabilités de transition en comptant des millions d’actions historiques, résolvez le point fixe, et le terrain acquiert une surface de valeur : proche de zéro dans votre propre coin, gonflant à travers le milieu, s’accentuant brusquement à l’intérieur de la surface.
Maintenant le mouvement élégant. La valeur d’une passe, de toute action, est la différence qu’elle fait :
C’est la menace attendue (xT), popularisée dans la formulation de Karun Singh (2019) [11] (2019). Introducing Expected Threat (xT). The value-surface formulation that made Markov possession value a public language. , avec des racines intellectuelles dans le cadre markovien de Sarah Rudd (2011) [10] (2011). A Framework for Tactical Analysis and Individual Offensive Production Assessment in Soccer Using Markov Chains. NESSIS. Possession as a Markov process, years ahead of its industry. , un travail qu’elle a présenté des années avant de rejoindre la direction d’un club de Premier League. Son cousin académique, le VAEP ( Decroos et al., KDD 2019 [12] (2019). Actions Speak Louder than Goals: Valuing Player Actions in Soccer. KDD 2019. VAEP; every action priced in both directions. ), étend l’idée à toutes les actions avec ballon et dans les deux sens du jeu : chaque touche est notée selon combien elle élève votre probabilité de marquer et abaisse votre probabilité d’encaisser, dans les quelques actions suivantes.
La conséquence est une révolution tranquille sur qui reçoit le crédit. Buts et passes décisives récompensent les deux dernières touches d’une action ; le xT et le VAEP paient le travail invisible : la passe latérale de l’arrière qui a retourné la surface de valeur, le demi-tour du milieu entre les lignes. Quand les comptes rendus de match de FootDigest insistent sur le fait qu’un milieu relayeur bas fut le joueur décisif du match malgré une feuille de match vierge, c’est cette équation de point fixe qui insiste.
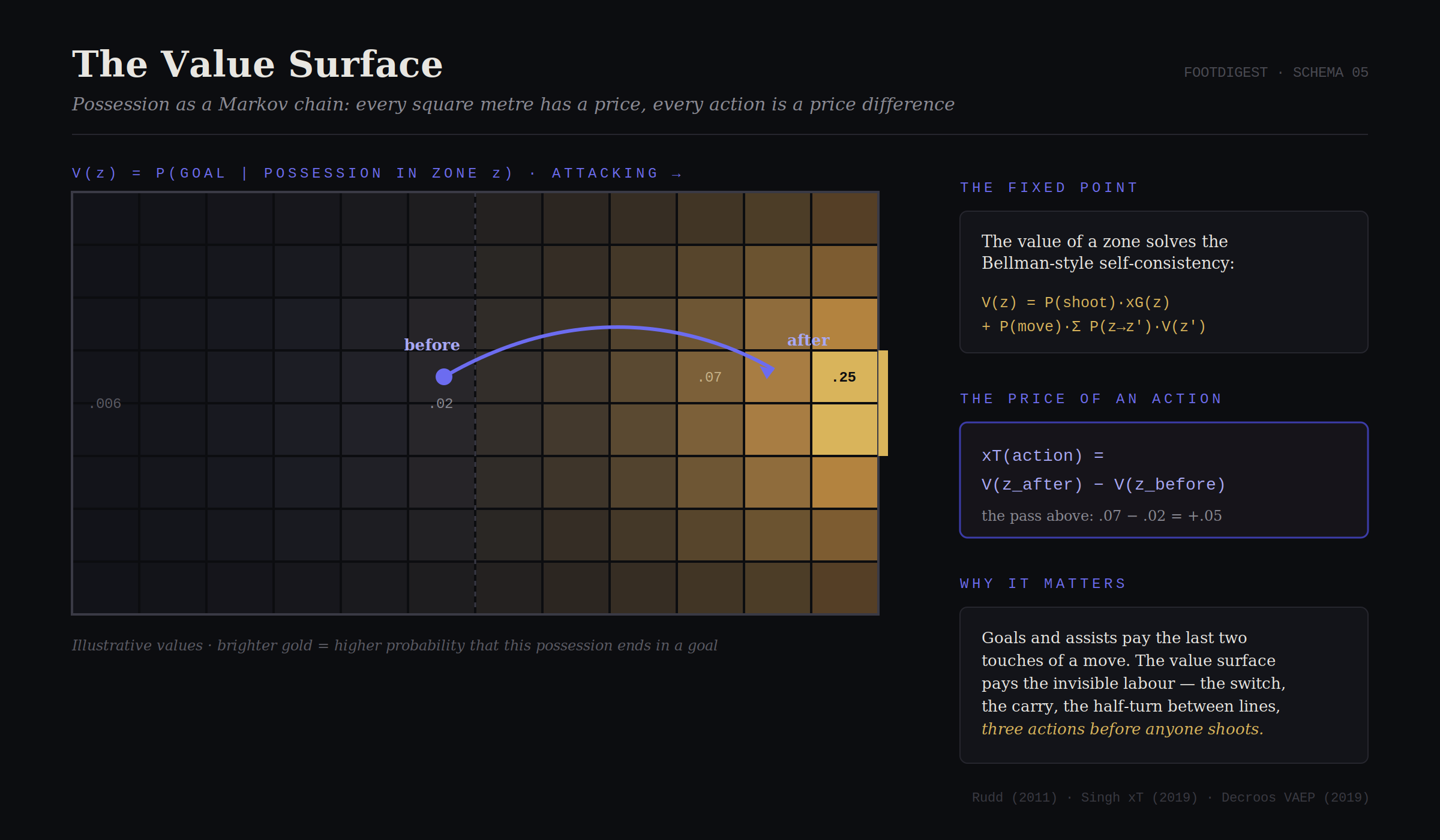
Figure 4 : touchez deux zones pour chiffrer une passe : la différence entre là où le ballon était et là où il est maintenant. (Surface illustrative.)
PARTIE VII : LA GÉOMÉTRIE DE L’ESPACE
Voronoi, contrôle du terrain et le football vu comme un graphe
Tout jusqu’ici chiffre des événements : buts, frappes, passes. Mais les entraîneurs ne pensent pas en événements ; ils pensent en espace. Et l’espace a été rigoureusement mathématisé.
VII.1 · À qui appartient le terrain
À tout instant figé, quel joueur contrôle quelle région ? La réponse au premier ordre est une tessellation de Voronoi : assignez chaque point du terrain au joueur le plus proche. Formellement, la cellule du joueur p est
Le terrain éclate en 22 polygones convexes, et la tactique devient géométrie visible. Un bloc bas compact : de minuscules cellules défensives, affamant l’adversaire de polygones centraux. Une transition étirée : de vastes cellules non gardées derrière les latéraux, précisément l’espace que les remplaçants de la Belgique ont inondé pendant ces trois minutes à Seattle, quand le bloc du Sénégal, protégeant son avance, est descendu de dix mètres et a cédé entièrement les polygones du milieu. (La Partie X revient sur pourquoi protéger une avance invite cela ; la géométrie et la théorie des probabilités du phénomène sont un même fait vu de deux côtés.)
Le Voronoi brut suppose que tous les joueurs sont également rapides, actuellement immobiles et infiniment attentifs. Le modèle de contrôle du terrain de William Spearman [13] (2018). Beyond Expected Goals. MIT Sloan Sports Analytics Conference. Pitch control: physics-aware ownership of space. (développé à Liverpool FC ; Beyond Expected Goals, Sloan 2018) corrige cela physiquement : pour chaque point, on calcule la probabilité que chaque équipe arrive la première si le ballon y était joué, en intégrant les vitesses actuelles, les limites d’accélération et le temps de trajet du ballon lui-même. La sortie est une surface continue de probabilité de possession sur le terrain, rafraîchie à la fréquence des données de suivi (25 Hz). Fernández et Bornn, Wide Open Spaces (Sloan 2018) [14] (2018). Wide Open Spaces. MIT Sloan Sports Analytics Conference. Space valued by threat, closing the loop between Parts VI and VII. bouclent la boucle en pondérant l’espace contrôlé par sa valeur : l’espace ne vaut que ce que la surface de valeur de la Partie VI dit qu’il menace.
VII.2 · L’équipe comme un graphe
Des mêmes données de suivi et d’événements tombent d’autres objets géométriques :
- Les enveloppes convexes, le plus petit polygone contenant les joueurs de champ d’une équipe : l’aire de l’enveloppe mesure la compacité (les équipes de pressing la réduisent ; les équipes de possession la gonflent), et la hauteur du centroïde de l’enveloppe mesure le courage collectif.
- Les réseaux de passes : les joueurs comme nœuds, les fréquences de passe comme arêtes pondérées, et soudain soixante ans de théorie des graphes s’appliquent gratuitement. La centralité d’intermédiarité identifie le métronome : retirez le nœud De Bruyne et le réseau belge perd l’essentiel de son débit. Les coefficients de clustering exposent le jeu en triangle. Et l’entropie de la distribution des passes mesure l’imprévisibilité : les grandes équipes offensives sont des objets à haute entropie, coûteux à compresser et donc coûteux à défendre.
Voici ce que je trouve discrètement profond : les formations ont toujours été des graphes, et la tactique a toujours été de la géométrie : il nous manquait simplement les capteurs. « 4-4-2 » est une compression avec perte, lisible par un humain, d’un graphe dynamique à 22 nœuds échantillonné 25 fois par seconde. Quand un commentateur dit qu’une équipe est « compacte entre les lignes », il existe désormais une aire de polygone et une distribution de tailles de cellules pour cela. Le vocabulaire de Cruyff et celui de la géométrie algorithmique se révèlent être la même langue en deux notations, séparées par cinquante ans d’instrumentation manquante.

Figure 5 : déplacez n’importe quel joueur et la carte de propriété se réorganise. Chargez le préréglage « Seattle, 79e minute » pour voir une avance protégée céder les polygones du milieu.
PARTIE VIII : LA THÉORIE DES JEUX À ONZE MÈTRES
Le seul endroit du sport où un théorème de 1928 est testé chaque semaine
Dans la nuit du 29 juin, cette Coupe du monde a mis en scène une expérience contrôlée. Maroc 1–1 Pays-Bas, tirs au but : Maroc qualifié, 3–2. Allemagne 1–1 Paraguay, tirs au but : Paraguay qualifié, 4–3. Deux séances, deux géants éliminés, une nuit, et sous les deux, le laboratoire réel le plus pur qui existe pour le théorème minimax de John von Neumann.
Un penalty est un jeu à deux joueurs et à somme nulle quasi idéal. Le tireur choisit un côté ; le gardien, contraint par des temps de vol du ballon d’environ 0,3 seconde face à des temps de réaction humains, doit s’engager essentiellement simultanément. Simplifiez les choix des deux joueurs à et la logique de l’équilibre en stratégies mixtes mord aussitôt : si vous frappez trop souvent de votre côté naturel, les gardiens l’exploitent ; tout schéma est une fuite. Le théorème de 1928 de von Neumann dit que le jeu optimal est une randomisation calibrée avec précision : mélangez vos choix de sorte que le gain espéré de votre adversaire soit identique quel que soit le côté où il plonge, ne lui laissant rien à exploiter. Le mélange d’équilibre n’est pas 50/50 ; il dépend de vos probabilités de marquer dans chaque cellule de la matrice de gains (les tireurs sont plus forts de leur côté naturel, donc l’équilibre penche vers le naturel, mais il ne fait que pencher).
Ce qui élève cela de l’exemple de manuel à la science empirique, c’est que des footballeurs professionnels ont été testés contre le théorème, et l’ont passé. Ignacio Palacios-Huerta (Review of Economic Studies, 2003) [7] (2003). Professionals Play Minimax. Review of Economic Studies 70. Penalty kicks as an empirical test of von Neumann; professionals pass. a rassemblé plus d’un millier de penalties professionnels et a vérifié les deux prédictions tranchantes du minimax : (1) la probabilité de marquer d’un tireur devrait être statistiquement identique entre ses stratégies (si frapper à gauche rapportait plus que frapper à droite, il devrait frapper à gauche davantage jusqu’à ce que l’écart se referme) et (2) les séquences de choix devraient être sérialement indépendantes, sans schéma, inexploitables. Les deux ont tenu. Une étude parallèle de Chiappori, Levitt et Groseclose (American Economic Review, 2002) [8] (2002). Testing Mixed-Strategy Equilibria When Players Are Heterogeneous. AER 92. Independent confirmation on French and Italian penalties. est arrivée à la même conclusion sur des données françaises et italiennes. Des footballeurs professionnels, dont la plupart n’ont jamais entendu le mot « minimax », jouent l’une des rares approximations humaines connues d’un équilibre exact de théorie des jeux, parce que pendant un siècle, la déviation a été impitoyablement sélectionnée à la baisse. La théorie fonctionne ici précisément parce que l’argent et le darwinisme sont réels.
Et puis, une coda de prudence dans la même littérature, une histoire de réplication que toute personne travaillant avec des données devrait se tatouer quelque part. Apesteguia et Palacios-Huerta (AER, 2010) [9] (2010 / 2012). Psychological Pressure in Competitive Environments. AER 100; Management Science 58. The first-kicker advantage and its contested replication; read as a pair. ont rapporté que l’équipe qui tire en premier dans une séance gagne environ 60 % du temps : un effet de pression psychologique, largement médiatisé, qui a poussé la FIFA à tester l’ordre de tir « ABBA ». Des études ultérieures sur de plus grands échantillons (notamment Kocher, Lenz et Sutter dans Management Science, 2012 [9] (2010 / 2012). Psychological Pressure in Competitive Environments. AER 100; Management Science 58. The first-kicker advantage and its contested replication; read as a pair. ) ont trouvé que l’avantage se réduisait vers l’insignifiance statistique. Le résumé honnête actuel : l’avantage du premier tireur est plausible, faible et contesté, et l’épisode est la crise de réplication de l’analyse du football en miniature. Les 60 % d’un jeu de données sont le pile ou face d’un autre. La règle de sourçage de FootDigest existe à cause d’histoires exactement comme celle-ci.

Figure 6 : tirez dix penalties contre un gardien qui apprend vos schémas. Puis lisez pourquoi votre seule défense était une pièce que vous ne lanciez pas. (Gains illustratifs.)
PARTIE IX : LES MACHINES APPRENANTES
Du comptage à l’observation
Tout jusqu’ici est de la statistique sur des événements. La frontière est l’apprentissage sur des trajectoires : des modèles qui ingèrent des données de position brutes et comprennent le jeu comme le fait l’œil d’un entraîneur. Une taxonomie de là où en est réellement le domaine, classée par maturité :
Les arbres à gradient boosté (XGBoost, LightGBM) restent les bêtes de somme de tout problème tabulaire : xG, classification d’issues, valorisation d’actions. Déraisonnablement efficaces, peu coûteux, et assez interprétables pour qu’on puisse discuter avec eux, ce qui, dans un environnement d’entraîneur, n’est pas un agrément mais une exigence de déploiement.
Les réseaux de neurones sur graphes traitent les 22 joueurs comme des nœuds portant positions et vitesses, et apprennent des fonctions respectant les symétries du jeu. Le jalon est le TacticAI de DeepMind ( Wang et al., Nature Communications, 2024 [15] (2024). TacticAI: an AI assistant for football tactics. Nature Communications 15, 1906. Geometric deep learning on 7,176 corners; the 90% preference result and its five-rater caveat. ), bâti avec Liverpool FC sur 7 176 corners de Premier League : il prédit le receveur du corner, prédit si une frappe suit (F1 ≈ 0,71) et, le saut génératif, propose des dispositifs défensifs ajustés qui réduisent la probabilité de frappe. En évaluation à l’aveugle, le staff de Liverpool a préféré les arrangements suggérés par TacticAI aux dispositifs réellement utilisés 90 % du temps. Note de rigueur, parce que cet article a promis de la rigueur : ces fameux 90 % viennent de cinq évaluateurs experts d’un seul club : réellement impressionnant, et réellement étroit, et ces deux faits appartiennent à la même phrase. Les coups de pied arrêtés, étant semi-statiques, étaient la première conquête naturelle. Le jeu ouvert est la guerre.
Les modèles de séquences, l’architecture transformeur derrière la vague actuelle d’IA, sont pointés vers les séquences de possession, apprenant la grammaire des attaques comme les modèles de langage apprennent des phrases. L’application fascinante est contrefactuelle : étant donné cette construction, qu’aurait joué ensuite une équipe d’élite typique ? La divergence entre la passe réelle et la distribution prédite par le modèle devient une définition mesurable de la créativité : la prise de décision d’Iliman Ndiaye, exprimée comme distance à l’attendu.
Et un aveu de métier, parce que je construis des systèmes de production pour gagner ma vie dans mon autre existence : le modèle n’est jamais la partie difficile. La partie difficile est la chaîne : ingérer des flux, réconcilier des identifiants de fournisseurs, survivre au match abandonné et au coup d’envoi reporté, versionner les cotes pour que l’article de mardi et celui de jeudi ne puissent pas se contredire en silence. FootDigest tourne sur la même discipline d’ingénierie que l’infrastructure de données de santé que j’ai bâtie pour des gouvernements : des tâches idempotentes, des journaux d’audit immuables, et la règle du produit déjà énoncée deux fois parce qu’elle est toute la constitution : des chiffres réels et sourcés, ou une absence assumée. Dans l’analyse du football, comme dans l’infrastructure publique, vous perdez la salle au premier chiffre que vous ne pouvez pas défendre.
PARTIE X : LÀ OÙ S’ARRÊTENT LES MATHÉMATIQUES
Revenons, enfin, à Seattle, parce que je vous dois la fin de cette histoire, et parce que la fin est la partie mathématiquement la plus intéressante de tout ce tournoi.
Sénégal 2, Belgique 0, 79e minute, le genre d’avance qui, historiquement, survit plus de neuf fois sur dix. Puis deux buts en trois minutes. Quiconque a ajusté des modèles en cours de jeu sait que l’hypothèse de Poisson à taux constant meurt précisément ici, et meurt d’une manière mesurée : l’intensité de marque dépend de l’état. Une équipe menée tard dans un match à élimination directe attaque avec un risque réalloué ; le bloc de l’équipe qui mène descend ; λ devient λ(état, temps), montant pour le camp aux abois exactement quand le match compte le plus, les effets de score bien documentés de la littérature en cours de jeu. Simultanément, la géométrie de la Partie VII raconte la même histoire de l’autre côté : le bloc plus profond cède les cellules de Voronoi du milieu, le contrôle du terrain migre vers l’équipe menée, et la surface de valeur sous ses possessions gonfle. La théorie des probabilités et la géométrie sont un seul phénomène portant deux notations. Un modèle correctement dépendant de l’état donnait à la Belgique plus que le modèle naïf, et malgré tout seulement un chemin étroit. La Belgique l’a pris.
Puis les prolongations, et un penalty du genre qu’aucun vecteur de variables sur Terre n’encode : le jugement d’un arbitre à la frontière de l’interprétable, revu, confirmé, décisif. La tentation est de dire que les mathématiques ont échoué. Ce n’est pas le cas. Les mathématiques ont dit rare, et rare n’est pas impossible, et la distance entre ces deux mots est là où vit le football.
Alors laissez-moi clore la partie technique de cet article par ses trois phrases les plus importantes, chacune gagnée à la dure :
1. La calibration est la seule vertu, et c’est une maigre consolation. Un bon modèle n’est pas celui qui « a choisi le vainqueur » ; c’est celui dont les prédictions à 70 % se réalisent 70 % du temps, vérifiable seulement sur des centaines de matchs via les règles de notation de la Partie III. N’importe quel soir, dans n’importe quel stade, un modèle parfaitement calibré peut voir, et verra, son favori mourir. Il est conçu pour cela.
2. Les queues appartiennent aux humains. Penalties accordés et penalties manqués, cartons rouges, interventions de la VAR, la jambe d’un gardien redirigeant la frappe de Jackson sur le poteau plutôt qu’à l’intérieur : cela vit dans le résidu, la variance qu’aucune variable n’explique. Les meilleurs modèles d’issue de match d’aujourd’hui, le mien compris, laissent la majorité de la variance des résultats inexpliquée. Ce résidu n’est pas un échec de méthode. Ce résidu est le jeu.
3. Une distribution n’est pas un destin. Le fatalisme coupe dans les deux sens, et les deux sont des mésusages des maths. Après que le Sénégal eut perdu ses deux premiers matchs (contre la France, puis la Norvège) les salons de Dakar l’avaient déjà enterré ; le modèle, insensible à l’arithmétique des huit meilleurs troisièmes, en faisait toujours mieux qu’un pari à deux contre trois pour passer, et il est passé, cinq à zéro contre l’Irak avec la survie en jeu. L’erreur inverse est pire : lire une probabilité à un chiffre comme un zéro. L’Afrique du Sud a atteint les phases à élimination directe pour la première fois de son histoire. Le groupe G s’est réordonné sept fois en une soirée, la dernière à la largeur d’une ligne de VAR. Chacun de ces faits était un événement de queue. Les queues ne sont pas le mode de défaillance du football. Les queues sont le produit.
Coda : 2002, et pourquoi je construis
Il y a un match que mon modèle n’a jamais vu, parce qu’il précède de deux décennies l’horizon de dépréciation de mes données : le 31 mai 2002. Sénégal 1, France 0. Les champions du monde en titre, battus au match d’ouverture de la Coupe du monde par une nation débutante. Chaque Sénégalais de ma génération porte ce score comme une tache de naissance. Quand le tirage de ce mois de juin a produit France–Sénégal, la première rencontre officielle depuis, aucun paramètre d’aucun modèle sur Terre n’encodait ce que cette affiche signifiait.
C’est là tout l’enjeu, au fond. Les mathématiques ne remplacent pas le sens ; elles donnent au sens une colonne vertébrale. Quand la Qualification Watch garde foi en votre équipe à zéro point, se fiant à l’arithmétique des huit meilleurs troisièmes que tout le quartier avait abandonnée, et que les maths sont validées, la joie n’est pas plus petite pour avoir été quantifiée ; elle est plus aiguë, parce que vous saviez que la porte était plus large que ne le croyait le deuil dans la pièce. Et quand la queue arrive vêtue de rouge, en prolongation, à Seattle, le deuil est réel et le modèle est intact, et une grande personne a le droit de tenir les deux.
Poisson nous donne le hasard, et Ben-Naim nous en donne la mesure. Dixon–Coles nous donne les cotes ; Brier et le RPS les tiennent honnêtes. Monte Carlo nous donne les futurs, leurs deux couches. La trigonométrie chiffre la frappe ; Markov chiffre tout ce qui précède ; Voronoi cartographie le sol où cela se produit ; von Neumann gouverne sa forme finale, la plus solitaire. L’apprentissage automatique nous donne des yeux que nous n’avions pas. Et le football (têtu, avare en buts, mesurablement le grand jeu le moins prévisible que les humains aient inventé) nous donne la raison de continuer à calculer.
Beyond scores. Football, distilled.
Annexe A : la fiche technique du modèle FootDigest
Une prédiction que vous ne pouvez pas auditer est une opinion avec des étapes en plus. Spécification du moteur derrière chaque probabilité de cet article :
Classe de modèle. Un modèle de scores Dixon–Coles piloté par Elo : la force d’une équipe est une unique cote World Football Elo ; l’écart de cotes devient une suprématie de buts qui se scinde en deux taux de buts de Poisson, corrigés sur les cellules de scores faibles par le facteur τ de Dixon–Coles. Les issues de tournoi proviennent d’une simulation de groupe de Monte Carlo par-dessus ce modèle de scores.
Paramètres. Une cote Elo par équipe (départ 1500, facteur K 40, +100 sur terrain non neutre à domicile, multiplicateur de différence de buts). Correspondance des scores : base de 2,6 buts, 170 points Elo par but de suprématie, dépendance des scores faibles ρ = −0,1. Avantage de l’hôte appliqué uniquement sur les terrains non neutres.
Données d’entraînement. Le jeu de données ouvert martj42/international_results (CC0) : chaque international senior masculin joué, 1872 à aujourd’hui (≈49 400 matchs à l’heure d’écrire), toutes compétitions, mis en miroir et resynchronisé quotidiennement.
Estimation. Les cotes Elo sont mises à jour en ligne après chaque match (une estimation ponctuelle, recalculée depuis tout l’historique à chaque synchronisation du jeu de données) ; les constantes de Dixon–Coles sont fixées, pas ajustées. Un Dixon–Coles attaque/défense ajusté par maximum de vraisemblance pondéré dans le temps a été évalué comme alternative et n’a pas surpassé le modèle de force Elo hors échantillon, donc le modèle plus simple est livré.
Simulation. 1 000 complétions de groupe de Monte Carlo ensemencées par mise à jour ; réglementation FIFA 2026 complète, y compris le classement des huit meilleurs troisièmes et tous les départages. Les probabilités rapportées ne portent que le bruit d’échantillonnage de Monte Carlo : l’incertitude sur les paramètres n’est pas propagée.
Validation. Backtestée hors échantillon sur les 2 607 internationaux joués depuis le 1er janvier 2024 (entraînée uniquement sur les matchs antérieurs) : RPS 0,173 contre une référence naïve de taux de base à 0,227, une réduction de 24 % ; la calibration est monotone avec une légère surconfiance sur les forts favoris à domicile. Une référence de marché (cotes de paris) et une comparaison à un réseau de neurones ne sont pas rapportées : ces données ne sont pas dans le système, et je ne citerai pas un chiffre que je ne peux pas calculer.
Modes de défaillance connus. La force d’une équipe est un unique scalaire (pas de séparation attaque/défense ajustée par équipe) sans décroissance temporelle de récence ; l’intensité de fin de match dépendante de l’état n’est pas modélisée (elle sous-pondère systématiquement les poussées de l’équipe menée, voir Seattle) ; les chocs d’effectif (blessures, suspensions) n’entrent que par la dérive Elo ; il n’y a aucune information intra-match au niveau du joueur.
Probabilité de victoire en cours de match (prototype de recherche). La trajectoire minute par minute de la figure d’ouverture n’est pas produite par le moteur livré, qui ne porte aucune information intra-match (ci-dessus). Elle a été calculée hors ligne à partir des données d’insights du match en direct, en conditionnant le modèle de scores d’avant-match au score courant et aux minutes restantes — un prototype d’une fonctionnalité en cours de jeu que je compte intégrer à FootDigest, présentée ici à titre d’illustration, non comme une capacité en production.
(Chaque chiffre de cette fiche est mesuré depuis le moteur en direct ou son backtest ; la seule quantité calculée hors ligne, la trajectoire d’ouverture en cours de match, est signalée comme prototype juste au-dessus. Des chiffres réels et sourcés, une absence assumée pour ce que les données ne peuvent pas encore soutenir.)
Annexe B : bibliographie annotée
- Moroney, M.J. (1956). Facts from Figures. Penguin. Le premier traitement statistique sérieux des scores de football ; ajustements de Poisson et de binomiale négative.
- Reep, C. & Benjamin, B. (1968). « Skill and Chance in Association Football. » JRSS-A 131. L’article fondateur et l’erreur fondatrice ; à lire aux côtés de ses critiques comme vaccin permanent contre la négligence du dénominateur.
- Maher, M.J. (1982). « Modelling Association Football Scores. » Statistica Neerlandica 36. Structure de Poisson attaque/défense ; le squelette de tout ce qui a suivi.
- Dixon, M.J. & Coles, S.G. (1997). « Modelling Association Football Scores and Inefficiencies in the Football Betting Market. » JRSS-C 46. La bête de somme : correction τ, décroissance temporelle et démonstration de l’inefficience du marché en un seul article.
- Karlis, D. & Ntzoufras, I. (2003). « Analysis of Sports Data by Using Bivariate Poisson Models. » JRSS-D 52. L’alternative de principe à τ.
- Ben-Naim, E., Vazquez, F. & Redner, S. (2006). « Parity and Predictability of Competitions. » J. Quantitative Analysis in Sports 2(4). Plus de 300 000 matchs ; le football mesuré comme le sport majeur à la plus haute fréquence de surprises.
- Palacios-Huerta, I. (2003). « Professionals Play Minimax. » Review of Economic Studies 70. Les penalties comme test empirique de von Neumann ; les professionnels réussissent.
- Chiappori, P-A., Levitt, S. & Groseclose, T. (2002). « Testing Mixed-Strategy Equilibria When Players Are Heterogeneous. » AER 92. Confirmation indépendante sur des penalties français et italiens.
- Apesteguia, J. & Palacios-Huerta, I. (2010). « Psychological Pressure in Competitive Environments. » AER 100 ; et Kocher, M., Lenz, M. & Sutter, M. (2012), Management Science 58. L’avantage du premier tireur et sa réplication contestée ; à lire en paire.
- Rudd, S. (2011). « A Framework for Tactical Analysis and Individual Offensive Production Assessment in Soccer Using Markov Chains. » NESSIS. La possession comme processus de Markov, des années en avance sur son industrie.
- Singh, K. (2019). « Introducing Expected Threat (xT). » La formulation par surface de valeur qui a fait de la valeur de possession de Markov une langue publique.
- Decroos, T. et al. (2019). « Actions Speak Louder than Goals: Valuing Player Actions in Soccer. » KDD 2019. VAEP ; chaque action chiffrée dans les deux sens.
- Spearman, W. (2018). « Beyond Expected Goals. » MIT Sloan Sports Analytics Conference. Contrôle du terrain : possession de l’espace consciente de la physique.
- Fernández, J. & Bornn, L. (2018). « Wide Open Spaces. » MIT Sloan Sports Analytics Conference. L’espace valorisé par la menace, bouclant la boucle entre les Parties VI et VII.
- Wang, Z. et al. (2024). « TacticAI: an AI assistant for football tactics. » Nature Communications 15, 1906. Apprentissage géométrique profond sur 7 176 corners ; le résultat de préférence à 90 % et sa réserve des cinq évaluateurs.
Le moteur Dixon–Coles de FootDigest, ses backtests complets et la méthodologie de la Qualification Watch auront leur propre article technique compagnon, avec le code, si vous êtes assez nombreux à le demander. Vous savez où est le bouton.
Errata & mises à jour
Aucune correction à ce jour.